 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBraveGuard: From Open-World Threats to Safer Computer-Use Agents
May 31, 2026Computer-use agents extend language models from text generation to sustained interaction with files, terminals, browsers, and external tools. This shift creates safety risks that are difficult to detect from isolated prompts or final responses, because harm often emerges only through multi-step execution traces whose individual actions appear locally benign. We introduce BraveGuard, a self-evolving defense framework for training guard models from open-world threat signals and realistic agent trajectories. BraveGuard mines recent research sources to identify emerging risks and attack patterns, instantiates them as executable computer-use tasks, collects agent rollouts, and derives trajectory-level supervision for guard model training. As new threats and validation failures appear, the pipeline can be repeated, yielding an adaptive defense loop rather than a static, benchmark-driven training process. We instantiate BraveGuard by training multiple guard backbones, including Qwen3-Guard and Llama-Guard variants, and evaluate the resulting guards on trajectory-level agent-safety benchmarks. BraveGuard consistently improves safety detection across computer-use trajectories. On AgentHazard, it substantially improves detection accuracy over off-the-shelf guard models, with accuracy increasing from 38.79% to 82.38% under the averaged guard-model setting. These results show that guard supervision grounded in open-world threat discovery and realistic agent execution can improve safety monitoring beyond fixed taxonomies and synthetic prompt-level data. BraveGuard offers a scalable path toward adaptive defenses for computer-use agents facing evolving real-world risks.
When Alignment Isn't Enough: Response-Path Attacks on LLM Agents
May 04, 2026Bring-Your-Own-Key (BYOK) agent architectures let users route LLM traffic through third-party relays, creating a critical integrity gap: a malicious relay can modify an aligned LLM response after generation but before agent execution. We formalize this post-alignment tampering threat and show that, without end-to-end integrity, the relay can observe, suppress, or replace downstream messages, making even perfectly aligned LLMs ineffective against such attacks. We instantiate this threat as the Relay Tampering Attack (RTA), which performs multi-round strategic rewriting, minimal security-critical edits, and stealth restoration by resubmitting tampered outputs to the upstream LLM. Across AgentDojo and ASB with six LLMs, RTA achieves up to 99.1% attack success, outperforming prompt-injection baselines with modest overhead. Case studies on OpenClaw and Claude Code demonstrate real-world feasibility, and evaluations of four defenses show that none fully prevent RTA. Finally, we propose a time-based detection defense that mitigates RTA while preserving agent utility.
OOD-MMSafe: Advancing MLLM Safety from Harmful Intent to Hidden Consequences
Mar 10, 2026While safety alignment for Multimodal Large Language Models (MLLMs) has gained significant attention, current paradigms primarily target malicious intent or situational violations. We propose shifting the safety frontier toward consequence-driven safety, a paradigm essential for the robust deployment of autonomous and embodied agents. To formalize this shift, we introduce OOD-MMSafe, a benchmark comprising 455 curated query-image pairs designed to evaluate a model's ability to identify latent hazards within context-dependent causal chains. Our analysis reveals a pervasive causal blindness among frontier models, with the highest 67.5% failure rate in high-capacity closed-source models, and identifies a preference ceiling where static alignment yields format-centric failures rather than improved safety reasoning as model capacity grows. To address these bottlenecks, we develop the Consequence-Aware Safety Policy Optimization (CASPO) framework, which integrates the model's intrinsic reasoning as a dynamic reference for token-level self-distillation rewards. Experimental results demonstrate that CASPO significantly enhances consequence projection, reducing the failure ratio of risk identification to 7.3% for Qwen2.5-VL-7B and 5.7% for Qwen3-VL-4B while maintaining overall effectiveness.
Autoregressive, Yet Revisable: In Decoding Revision for Secure Code Generation
Feb 01, 2026Large Language Model (LLM) based code generation is predominantly formulated as a strictly monotonic process, appending tokens linearly to an immutable prefix. This formulation contrasts to the cognitive process of programming, which is inherently interleaved with forward generation and on-the-fly revision. While prior works attempt to introduce revision via post-hoc agents or external static tools, they either suffer from high latency or fail to leverage the model's intrinsic semantic reasoning. In this paper, we propose Stream of Revision, a paradigm shift that elevates code generation from a monotonic stream to a dynamic, self-correcting trajectory by leveraging model's intrinsic capabilities. We introduce specific action tokens that enable the model to seamlessly backtrack and edit its own history within a single forward pass. By internalizing the revision loop, our framework Stream of Revision allows the model to activate its latent capabilities just-in-time without external dependencies. Empirical results on secure code generation show that Stream of Revision significantly reduces vulnerabilities with minimal inference overhead.
A Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
Jan 16, 2026The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has driven major gains in reasoning, perception, and generation across language and vision, yet whether these advances translate into comparable improvements in safety remains unclear, partly due to fragmented evaluations that focus on isolated modalities or threat models. In this report, we present an integrated safety evaluation of six frontier models--GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5--assessing each across language, vision-language, and image generation using a unified protocol that combines benchmark, adversarial, multilingual, and compliance evaluations. By aggregating results into safety leaderboards and model profiles, we reveal a highly uneven safety landscape: while GPT-5.2 demonstrates consistently strong and balanced performance, other models exhibit clear trade-offs across benchmark safety, adversarial robustness, multilingual generalization, and regulatory compliance. Despite strong results under standard benchmarks, all models remain highly vulnerable under adversarial testing, with worst-case safety rates dropping below 6%. Text-to-image models show slightly stronger alignment in regulated visual risk categories, yet remain fragile when faced with adversarial or semantically ambiguous prompts. Overall, these findings highlight that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation design--underscoring the need for standardized, holistic safety assessments to better reflect real-world risk and guide responsible deployment.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
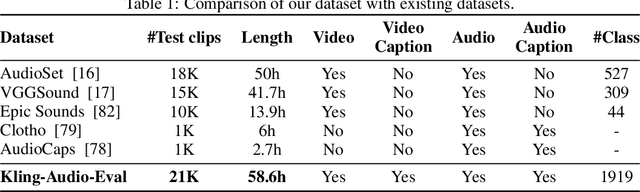
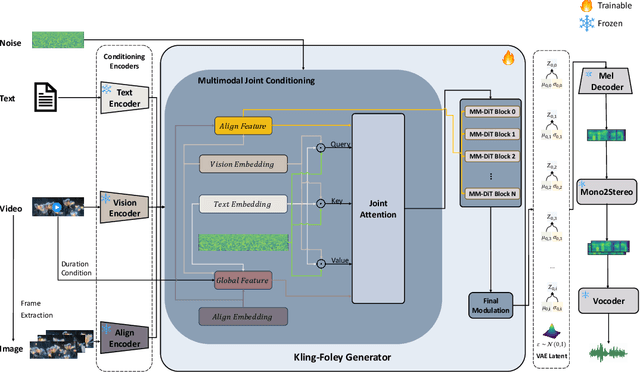
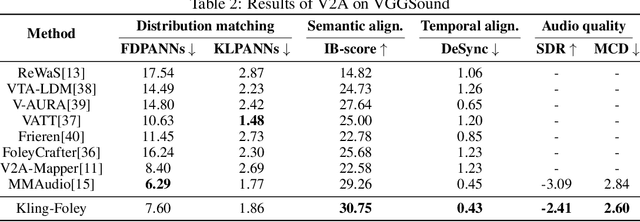
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Jul 08, 2024



The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning
Jun 06, 2024



Code Pre-trained Models (CodePTMs) based vulnerability detection have achieved promising results over recent years. However, these models struggle to generalize as they typically learn superficial mapping from source code to labels instead of understanding the root causes of code vulnerabilities, resulting in poor performance in real-world scenarios beyond the training instances. To tackle this challenge, we introduce VulLLM, a novel framework that integrates multi-task learning with Large Language Models (LLMs) to effectively mine deep-seated vulnerability features. Specifically, we construct two auxiliary tasks beyond the vulnerability detection task. First, we utilize the vulnerability patches to construct a vulnerability localization task. Second, based on the vulnerability features extracted from patches, we leverage GPT-4 to construct a vulnerability interpretation task. VulLLM innovatively augments vulnerability classification by leveraging generative LLMs to understand complex vulnerability patterns, thus compelling the model to capture the root causes of vulnerabilities rather than overfitting to spurious features of a single task. The experiments conducted on six large datasets demonstrate that VulLLM surpasses seven state-of-the-art models in terms of effectiveness, generalization, and robustness.
An Extensive Study on Adversarial Attack against Pre-trained Models of Code
Nov 23, 2023



Transformer-based pre-trained models of code (PTMC) have been widely utilized and have achieved state-of-the-art performance in many mission-critical applications. However, they can be vulnerable to adversarial attacks through identifier substitution or coding style transformation, which can significantly degrade accuracy and may further incur security concerns. Although several approaches have been proposed to generate adversarial examples for PTMC, the effectiveness and efficiency of such approaches, especially on different code intelligence tasks, has not been well understood. To bridge this gap, this study systematically analyzes five state-of-the-art adversarial attack approaches from three perspectives: effectiveness, efficiency, and the quality of generated examples. The results show that none of the five approaches balances all these perspectives. Particularly, approaches with a high attack success rate tend to be time-consuming; the adversarial code they generate often lack naturalness, and vice versa. To address this limitation, we explore the impact of perturbing identifiers under different contexts and find that identifier substitution within for and if statements is the most effective. Based on these findings, we propose a new approach that prioritizes different types of statements for various tasks and further utilizes beam search to generate adversarial examples. Evaluation results show that it outperforms the state-of-the-art ALERT in terms of both effectiveness and efficiency while preserving the naturalness of the generated adversarial examples.